
SparkR初探
分享
-
2016-05-15
好久没有发博客了,一是因为工作本身的事情挺多,第二是因为开发者大会,也正是由于开发者大会,所以虾神我又捡起了好多年不玩的大数据……好吧,好几个月没有玩的大数据了,捡起的方式,就是去github上看看esri那边对gis tools for hadoop这个东东有没有啥更新。
果然,让我发现了一个灰常重要的更新情况,如下图:
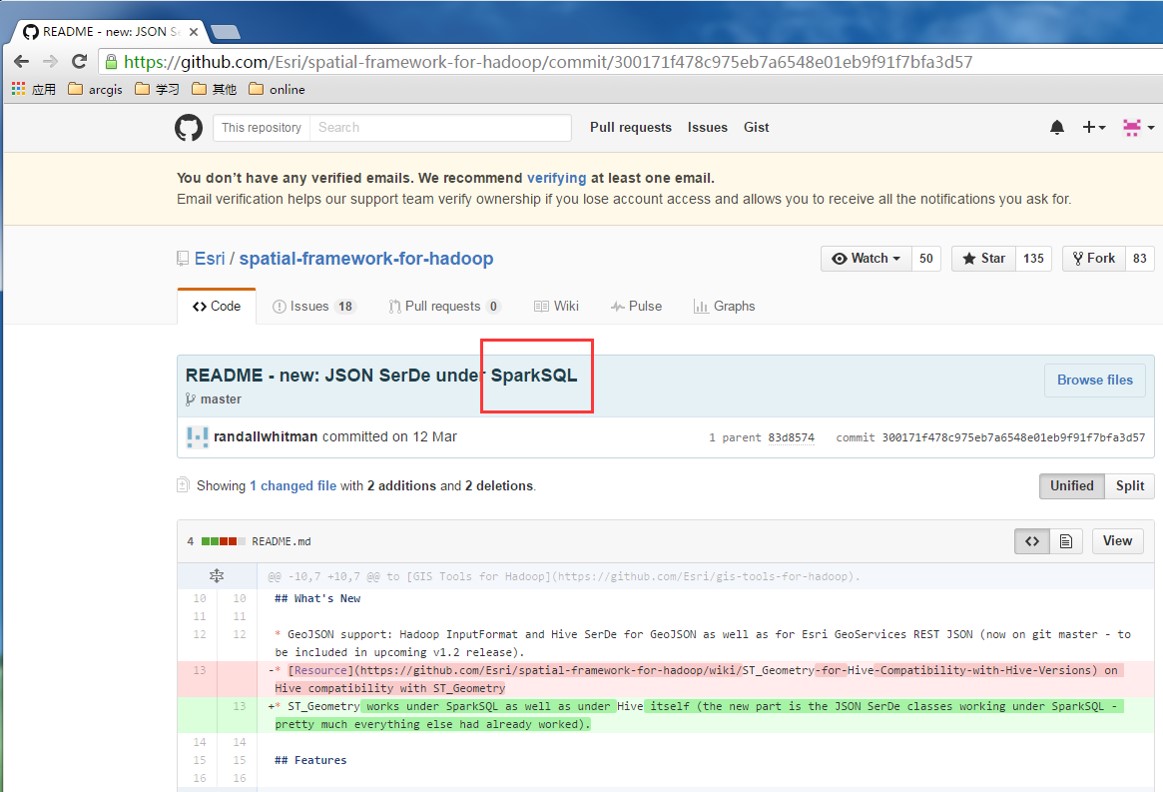
Spatial framework for hadoop里面,开始正式加入对Spark的支持了。从14年得到这个消息,足足等了2年啊……以至于我都开始怀疑Esri的hadoop团队被整体开掉了。(大家可以跟着我脑补:吃啥啥不剩,干啥啥不成,留你们何用。。。大数据这个东西又不能赚钱,还是调去写server做项目……)不过还好,等了这些年,终于发现更新了……当然,spark本来就可以利用hadoop提供的一切东东,比如里面的那些jar包,都是可以直接用,但是又更新,就说明人还在,真是一件值得欣慰的事情。
用周MM同学的话来说:这是个人的一小步,确是整个行业的一大步。
正因为如此,所以抽了个时间,把自己的整个hadoop环境全部做了一次大更新,当然,按照我一般的习惯,为了与以往的一些东西兼容,所以不会使用到最新的版本。
本次更新清单如下:
1、操作系统:
CentOS 7.1
2、hadoop版本:2.6.2
3、Scala 版本:2.11
4、Spark版本:1.6.0
附加其他工具包:
Linux 版 JDK1.8
Linux版 Python2.7
Linux版 R 3.2
Linux版 PyCharm 和Eclipse Mars2
实际上在安装的时候遇见了无数的问题,最大问题居然是CentOS 7的命令方式都换了……压根和6是完全两个不同的东东好吧。。。我第一天用这个版本的时候,居然连关机都关不上。。我那个囧啊。
好吧,前面啰啰嗦嗦讲了这么多,实际上仅仅是一个铺垫而已,这次博客主要是把这个好消息告诉一下大家,另外最后我留下了一份全套软件的安装手册(不过这个手册主要是为我自己进行记录了,其他同学要看,估计怕有些看不懂。)如果有需要这个手册的,
可以通过公众号获得的邮箱进行索取。
下面简单演示一下Spark的几个分析示例:
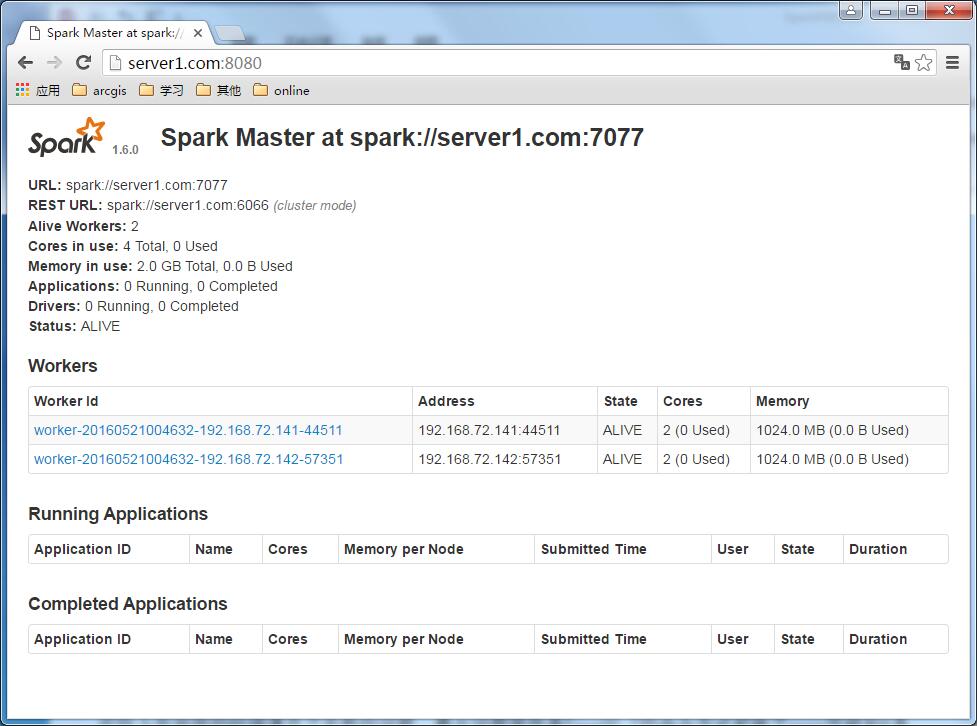
如果Spark正常启动,那么在没有任务之前,监控页面是这样的:
下面来启动两个示例
1、Python的:
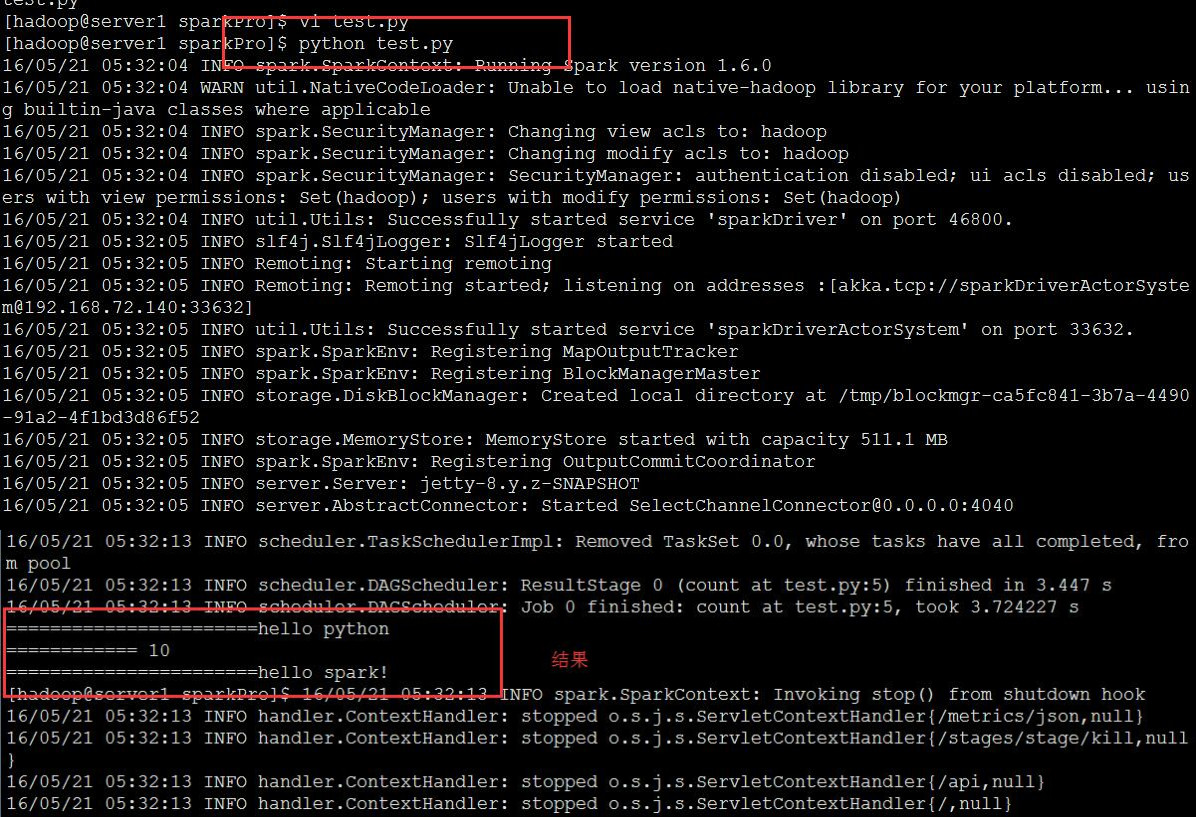
源代码: 意思就是从hdfs里面获取这个文件的内容,然后以Spark这个单词为分隔符,看看可以把整个文件切分成几段。

从第四行可以看出,我这个是直接提交到我的server1.com集群上面的,并非Local模式,测试任务的名字叫做 test app 20160521,然后我们直接运行一下:
运行的方式有两种,一是可以直接利用python来运行,这种方式需要配置了python的各种环境变量,一种就是通过pyspark来提交,我们直接用Python运行,如下;
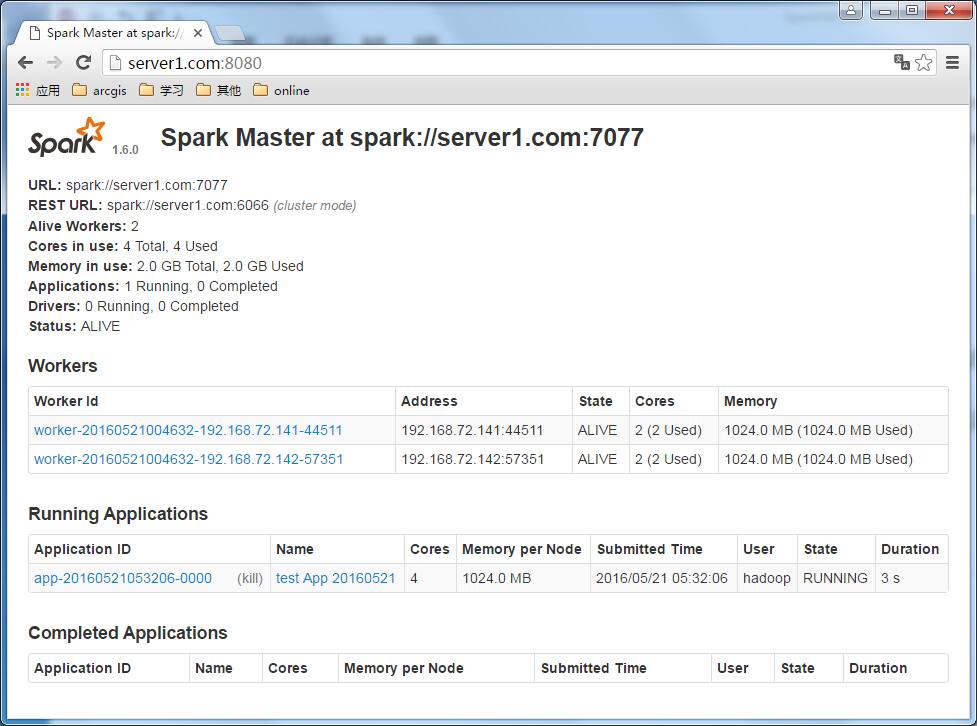
运行起来之后,监控界面就变成了这个样子:
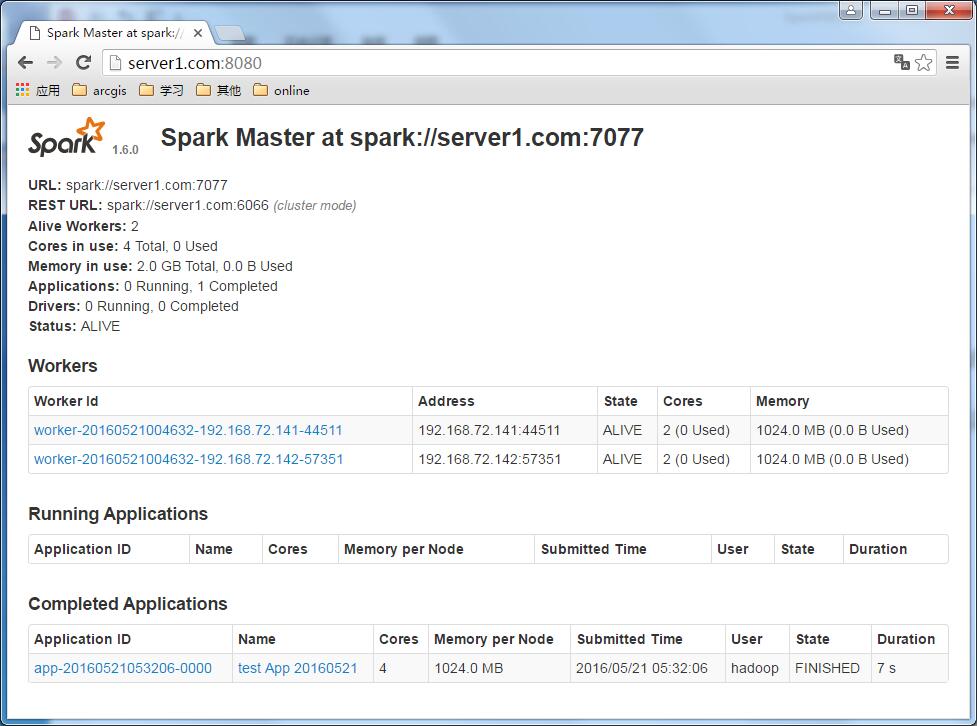
运行完成之后,是这样的。
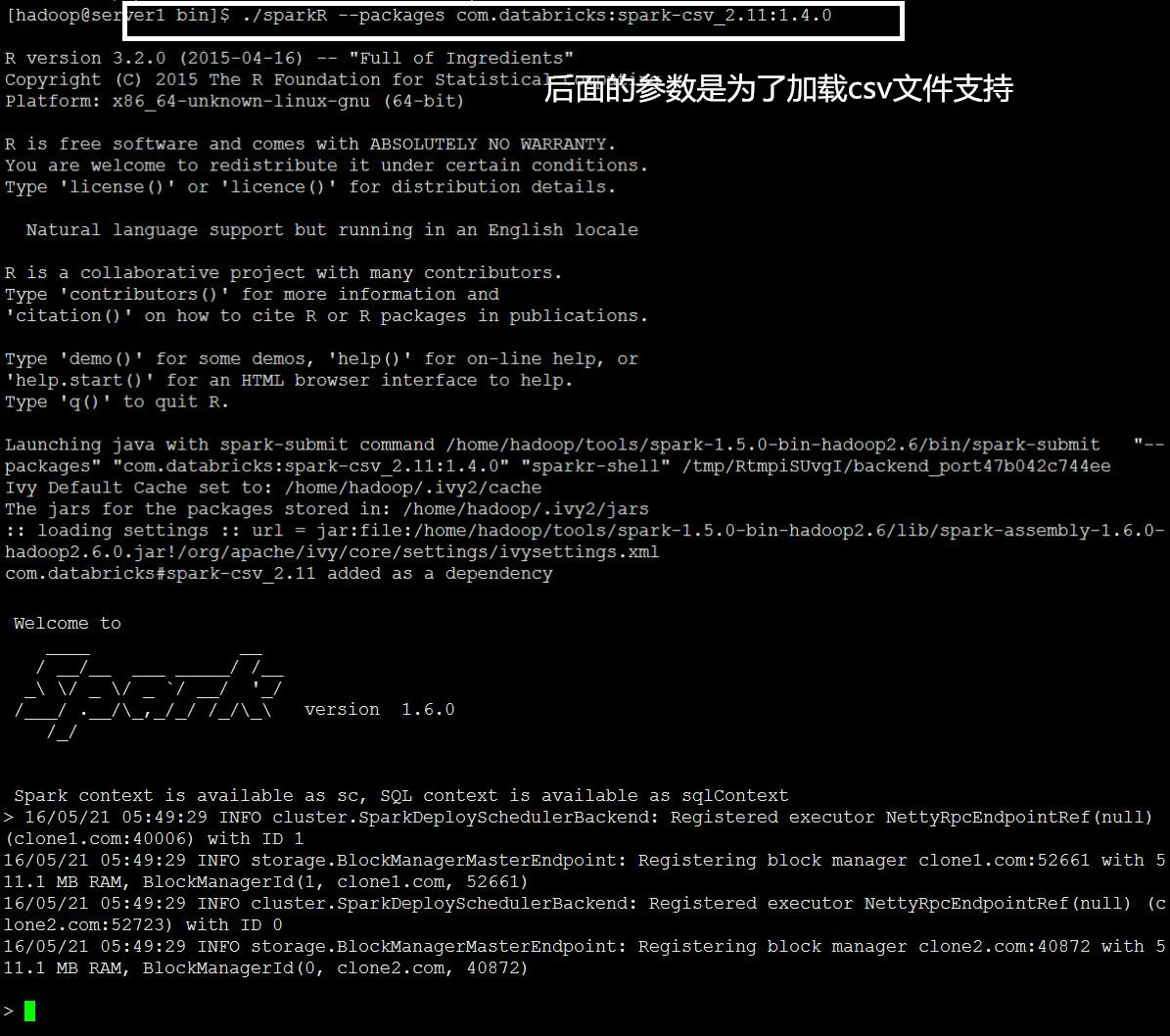
2、测试SparkR,这个东东比较神奇……看下面:
首先直接启动SparkR
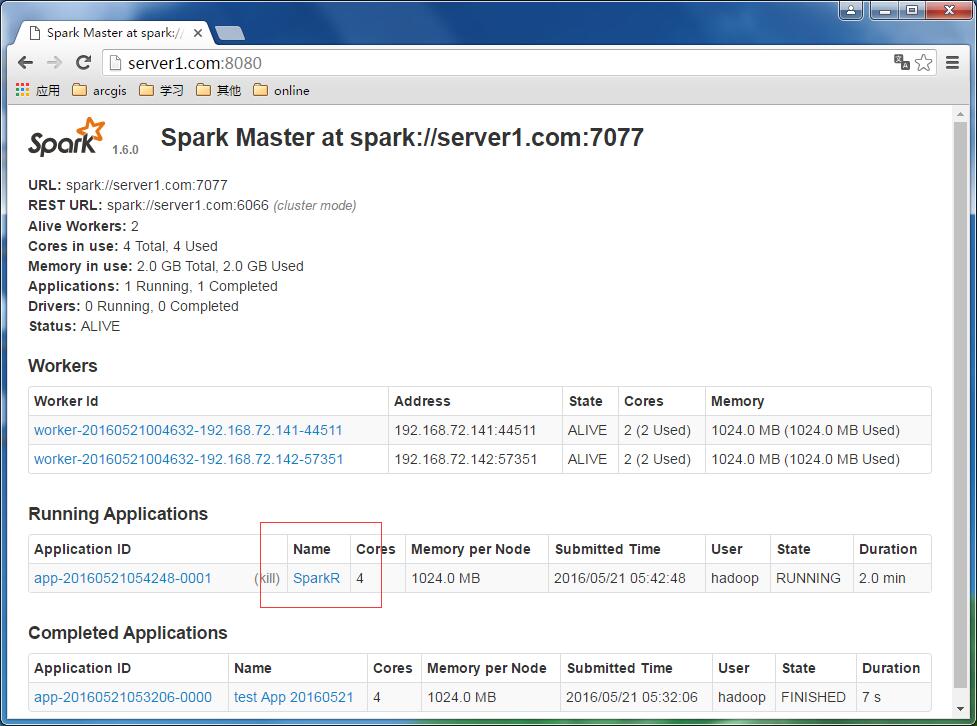
启动之后,在监控界面上就可以看见sparkR的运行情况了:
然后来运行一个R语言分析:
加载HDFS里面的数据:

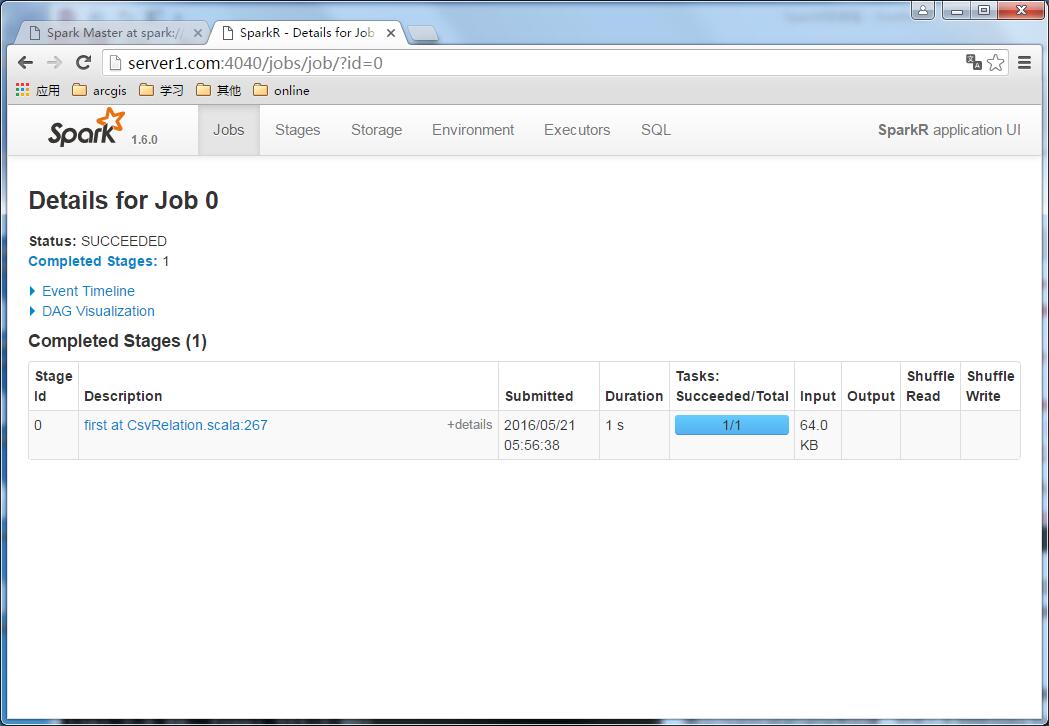
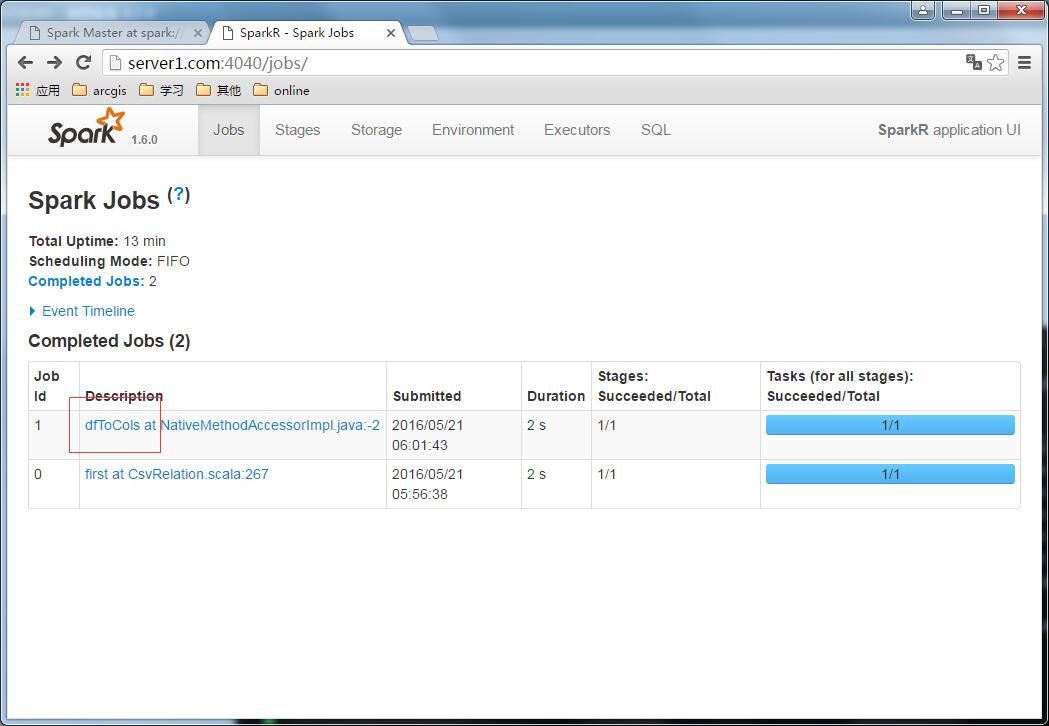
查看spark的任务监控,发现加载了一个文件:
查看一下这个csv里面有啥内容:
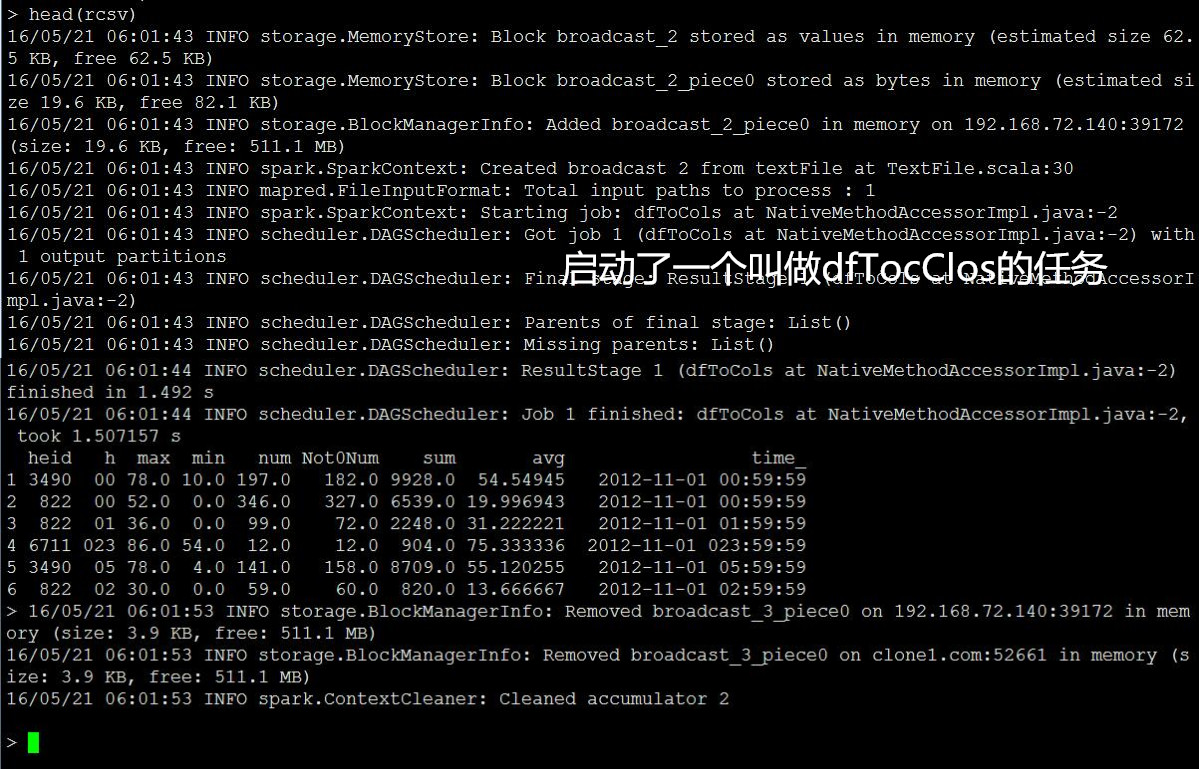
监控:
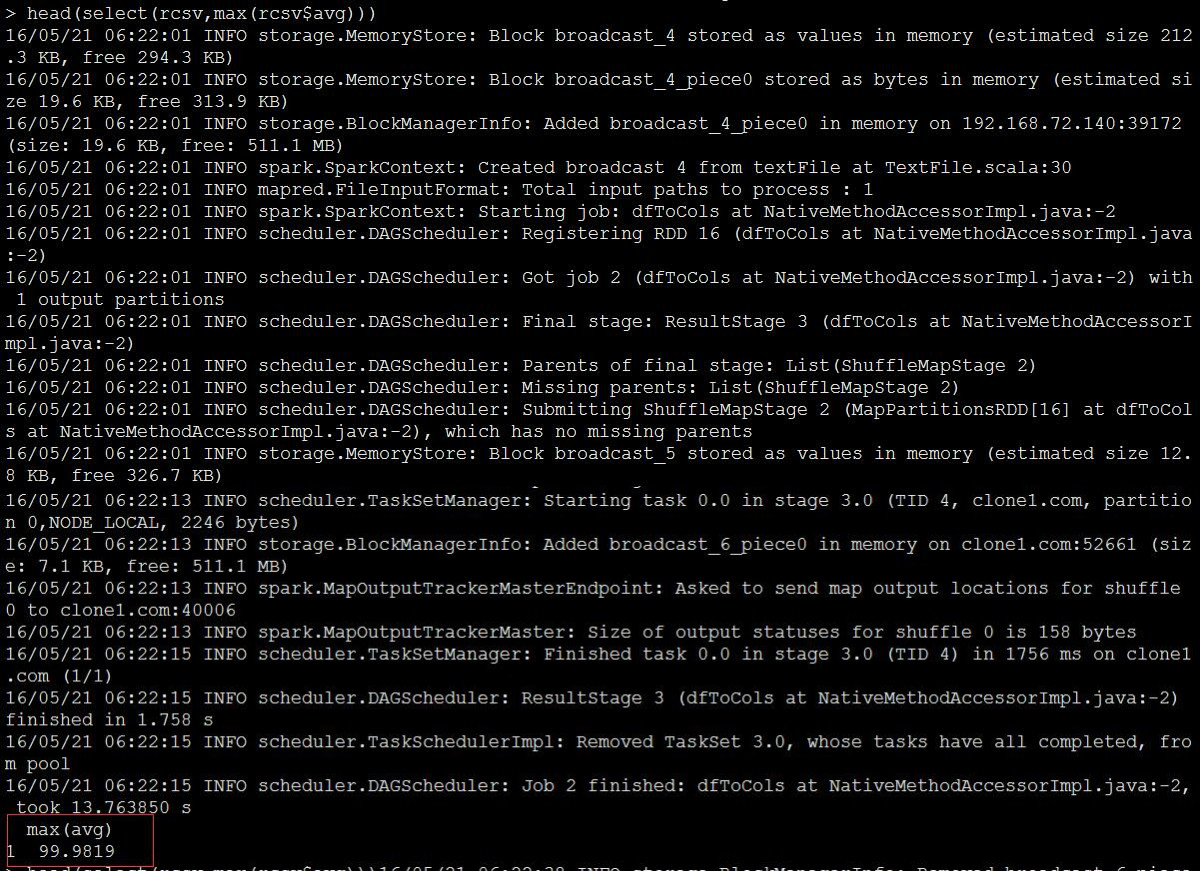
来一个max:
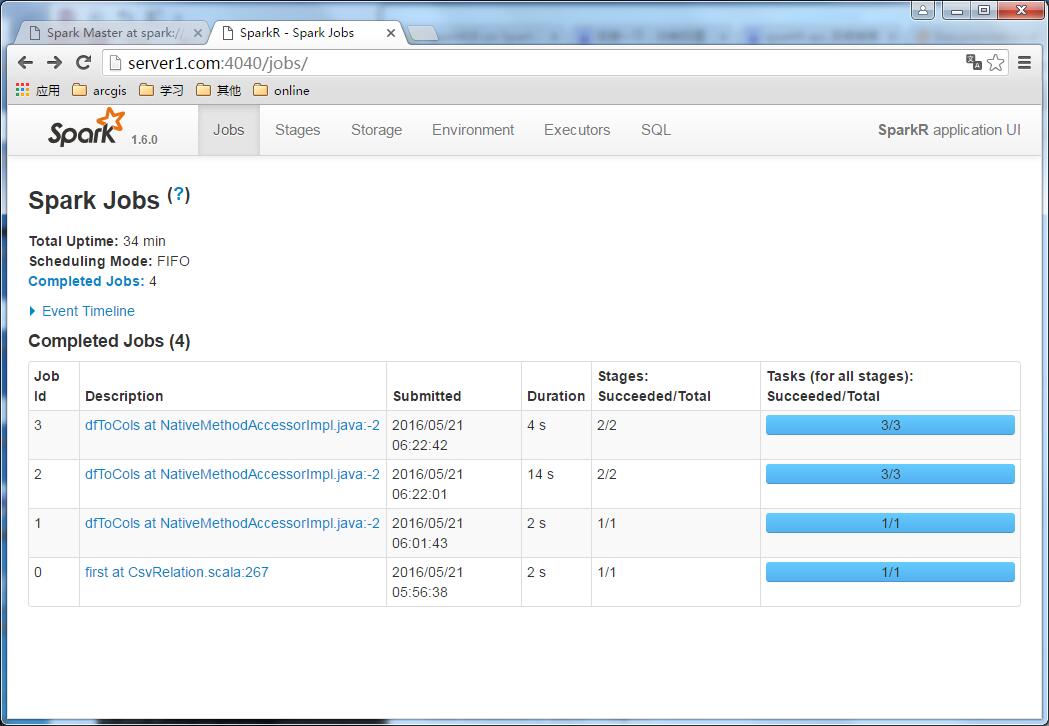
监控:
这样看来,大部分R的分析,都能够直接跑在spark集群上了,再联想到去年Esri发布了ArcGIS对R语言的支持,可以预料到不远的未来,所有的集群运算都将被融为一体。
还想了解更多的hadoop、spark以及R的内容,可以关注我的个人公众号,如果希望面对面交流,请与Esri中国相应的销售经理联系。
个人公众号

文章来源:http://blog.csdn.net/allenlu2008/article/details/51472485
果然,让我发现了一个灰常重要的更新情况,如下图:
Spatial framework for hadoop里面,开始正式加入对Spark的支持了。从14年得到这个消息,足足等了2年啊……以至于我都开始怀疑Esri的hadoop团队被整体开掉了。(大家可以跟着我脑补:吃啥啥不剩,干啥啥不成,留你们何用。。。大数据这个东西又不能赚钱,还是调去写server做项目……)不过还好,等了这些年,终于发现更新了……当然,spark本来就可以利用hadoop提供的一切东东,比如里面的那些jar包,都是可以直接用,但是又更新,就说明人还在,真是一件值得欣慰的事情。
用周MM同学的话来说:这是个人的一小步,确是整个行业的一大步。
正因为如此,所以抽了个时间,把自己的整个hadoop环境全部做了一次大更新,当然,按照我一般的习惯,为了与以往的一些东西兼容,所以不会使用到最新的版本。
本次更新清单如下:
1、操作系统:
CentOS 7.1
2、hadoop版本:2.6.2
3、Scala 版本:2.11
4、Spark版本:1.6.0
附加其他工具包:
Linux 版 JDK1.8
Linux版 Python2.7
Linux版 R 3.2
Linux版 PyCharm 和Eclipse Mars2
实际上在安装的时候遇见了无数的问题,最大问题居然是CentOS 7的命令方式都换了……压根和6是完全两个不同的东东好吧。。。我第一天用这个版本的时候,居然连关机都关不上。。我那个囧啊。
好吧,前面啰啰嗦嗦讲了这么多,实际上仅仅是一个铺垫而已,这次博客主要是把这个好消息告诉一下大家,另外最后我留下了一份全套软件的安装手册(不过这个手册主要是为我自己进行记录了,其他同学要看,估计怕有些看不懂。)如果有需要这个手册的,
可以通过公众号获得的邮箱进行索取。
下面简单演示一下Spark的几个分析示例:
如果Spark正常启动,那么在没有任务之前,监控页面是这样的:
下面来启动两个示例
1、Python的:
源代码: 意思就是从hdfs里面获取这个文件的内容,然后以Spark这个单词为分隔符,看看可以把整个文件切分成几段。
从第四行可以看出,我这个是直接提交到我的server1.com集群上面的,并非Local模式,测试任务的名字叫做 test app 20160521,然后我们直接运行一下:
运行的方式有两种,一是可以直接利用python来运行,这种方式需要配置了python的各种环境变量,一种就是通过pyspark来提交,我们直接用Python运行,如下;
运行起来之后,监控界面就变成了这个样子:
运行完成之后,是这样的。
2、测试SparkR,这个东东比较神奇……看下面:
首先直接启动SparkR
启动之后,在监控界面上就可以看见sparkR的运行情况了:
然后来运行一个R语言分析:
加载HDFS里面的数据:
查看spark的任务监控,发现加载了一个文件:
查看一下这个csv里面有啥内容:
监控:
来一个max:
监控:
这样看来,大部分R的分析,都能够直接跑在spark集群上了,再联想到去年Esri发布了ArcGIS对R语言的支持,可以预料到不远的未来,所有的集群运算都将被融为一体。
还想了解更多的hadoop、spark以及R的内容,可以关注我的个人公众号,如果希望面对面交流,请与Esri中国相应的销售经理联系。
个人公众号
文章来源:http://blog.csdn.net/allenlu2008/article/details/51472485

