
ArcMap中使用Python遇到中文字段名错误的解决方法
分享
-
2013-10-08
前一段时间遇到一个客户需要在ArcMap中批量的通过等高线图生成DEM,但是等高线图中的高程字段名称全部是中文,大家都知道Python遇到中文就会出现各种诡异状况,于是我被用户找去解决问题。
先看看Python的版本,是2.6.5,比用户的2.5.1要高,不知道这个问题能不能在自己电脑上重现。

好了,创建一个ChineseTest.py,内容如下:

测试一下,结果:
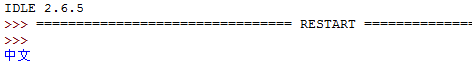
好吧,悲剧了,自己电脑上的版本比用户高,没法重现这个错误,只能到现场去解决了。
到用户现场,用上面的同样方式输出“中文”两个字,出现问题:

嗯,先把编码方式换成Utf-8尝试下:

错误依旧……
既然它提供了网址,那就看看吧。简单地浏览一下,终于知道如果文件里有非ASCII字符,需要在第一行或第二行指定编码声明。把ChineseTest.py文件的编码重新改为ANSI,并加上编码声明:
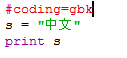
实验结果出来了:
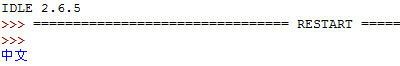
很好,成果喜人,接着就是用这个方式来代替我们在高程字段中使用的中文字符。
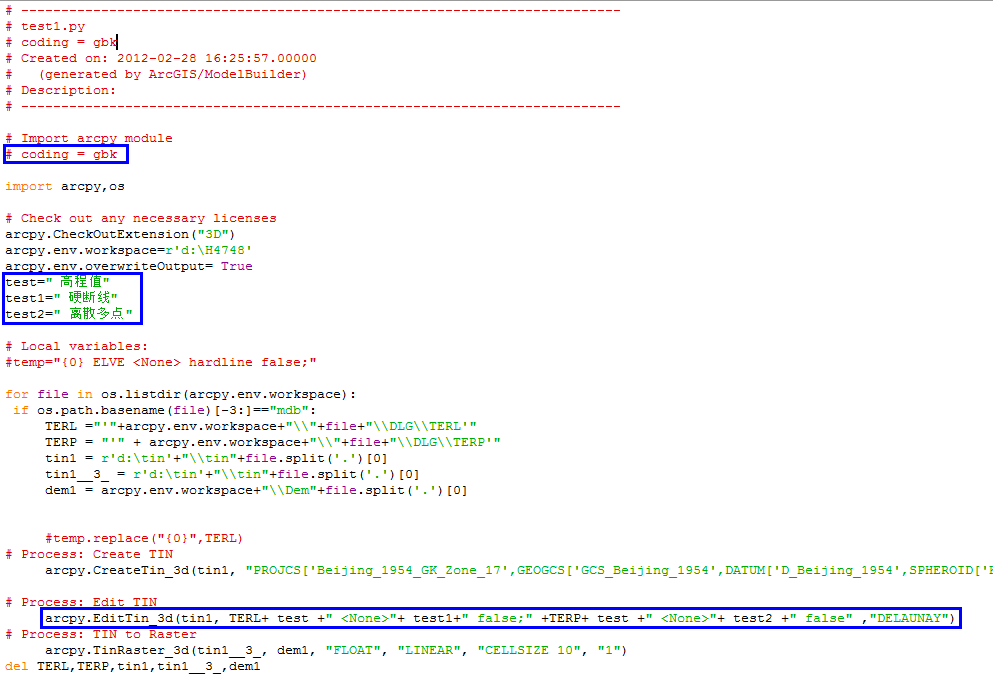
结果依然悲剧,报取不到这个字段(因为没有用户数据,无法在这里给大家截图看了)。
鼓捣了好长时间,依旧是这个问题,没有任何进展。我只能建议用户先把字段中的中文,改成英文别名,这样就OK了,理论上确实可行,但是用户有9000多个shp文件,改完都成仙了~~
继续研究,终于发现最终的解决办法需要先修改编码方式,再将中文字段转换成unicode就可以识别了。
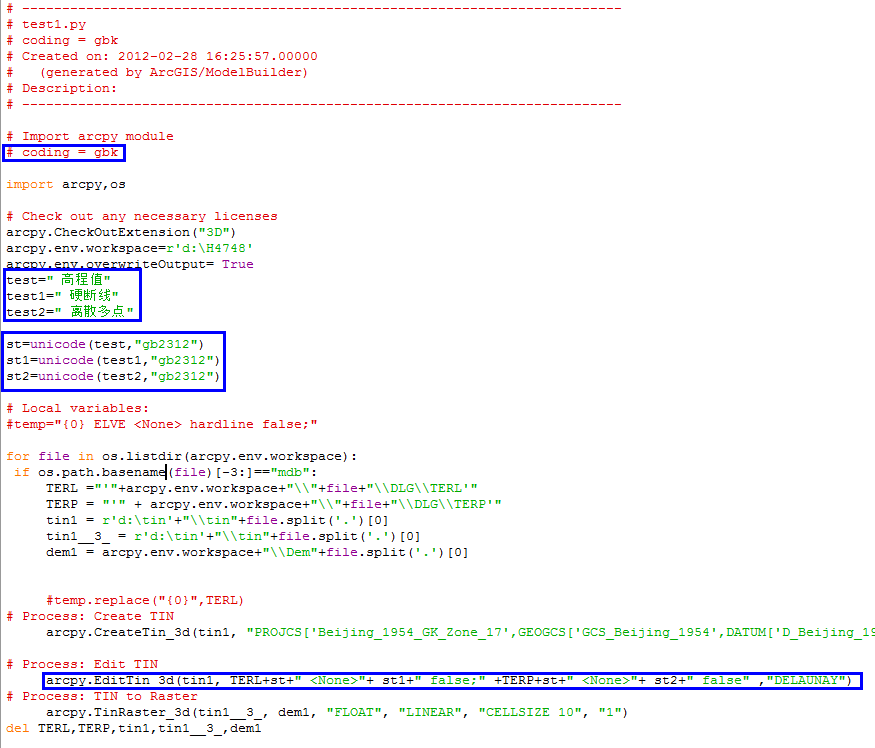
总结一下,解决方法是:
开头加上
#coding = gbk
之后将需要读取的中文字段名称转换为unicode,转换方法为:
s = “ 中文”
st = unicode(s,"gb2312") 这样就能安全的使用这些字段名了。
文章来源:http://blog.csdn.net/esrichinacd/article/details/7796155
先看看Python的版本,是2.6.5,比用户的2.5.1要高,不知道这个问题能不能在自己电脑上重现。
好了,创建一个ChineseTest.py,内容如下:
测试一下,结果:
好吧,悲剧了,自己电脑上的版本比用户高,没法重现这个错误,只能到现场去解决了。
到用户现场,用上面的同样方式输出“中文”两个字,出现问题:
嗯,先把编码方式换成Utf-8尝试下:
错误依旧……
既然它提供了网址,那就看看吧。简单地浏览一下,终于知道如果文件里有非ASCII字符,需要在第一行或第二行指定编码声明。把ChineseTest.py文件的编码重新改为ANSI,并加上编码声明:
实验结果出来了:
很好,成果喜人,接着就是用这个方式来代替我们在高程字段中使用的中文字符。
结果依然悲剧,报取不到这个字段(因为没有用户数据,无法在这里给大家截图看了)。
鼓捣了好长时间,依旧是这个问题,没有任何进展。我只能建议用户先把字段中的中文,改成英文别名,这样就OK了,理论上确实可行,但是用户有9000多个shp文件,改完都成仙了~~
继续研究,终于发现最终的解决办法需要先修改编码方式,再将中文字段转换成unicode就可以识别了。
总结一下,解决方法是:
开头加上
#coding = gbk
之后将需要读取的中文字段名称转换为unicode,转换方法为:
s = “ 中文”
st = unicode(s,"gb2312") 这样就能安全的使用这些字段名了。
文章来源:http://blog.csdn.net/esrichinacd/article/details/7796155

