
ArcGIS与插值(一): 统计与地统计
分享
-
2016-12-31
顾名思义,地统计就是针对地理数据的统计,用于分析和预测与空间或时空现象相关的值。而ArcGIS中的地统计拓展模块是实现使用确定性方法和地统计方法对空间数据进行描述性分析和插值分析功能的。
在工作中经常碰到这样的问题:我这组数据应该用什么插值比较好?ArcGIS中的这些插值方法哪个最快?哪个效果最好?
碰到这种问题,ArcGIS地统计模块帮助文档中给出了插值方法分类树,对应插值方法分类自己进行决策就行了。
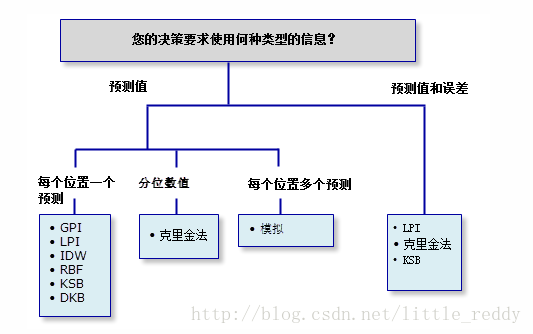
但实际情况并不如此简单,先不谈这个分类树中并没有介绍几种克里金插值的区别问题,其中很多分类也并不明确,比如不平滑、中等平滑和平滑这样含糊不清的分类就让人很难抉择;而且这个分类树最重要的问题是,很多专有名词并不容易被理解,比如:什么是假设条件的级别?什么是预测值的不确定性?什么是空间自相关?
我认为作为GIS从业人员或GIS学生,想要使用ArcGIS平台对空间数据进行插值,固然不需要非常专有的数学、统计知识,但是对统计、地统计的一些基本概念还是需要的。这个系列博客会把空间插值要用到的一下相关名称、原理做一些基本的介绍,并比较各个插值方法不同的适用性。
作为这个系列的第一篇博客,我在这里先介绍一些空间插值会应用到的基本的统计概念,然后将他们类比到地统计任务中。
一. 总体、样本、测量值和统计量
总体是考察对象的全体,样本是我们为了得知总体的一些信息而采集的对象集合,测量值顾名思义就是样本的值,而统计量是总体或样本值进行一些统计分析后得出的结果,如均值,极值等。
放到插值分析中来说,这片区域所有位置是总体,观测点为样本。但是要注意的是,不仅仅是观测点的值可以作为测量值计算相关统计量,观测点的位置、观测时间在地统计中也是重要的信息。
二. 两个重要的统计量
在统计分析中,数值型数据两个最重要的统计量分别是均值和方差。
均值是数据集中趋势的最重要测量值。从统计思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
方差是个变量值与平均数之差的平方的平均数。他在数学处理上是通过平方的办法消去差的正负号,然后进行平均。方差的平方根称为标准差。方差(或标准差)可以较好地反映出数据的离散程度,是实际中应用最广的离散程度测量值。
三. 描述性统计和推断性统计
统计操作可以分为两类,描述性统计和推断性统计。他们并不是并列存在的,推断性统计实际上实在描述性统计的基础上进行更深层次的分析。
四. 变量的连续性与随机变量的分布
对于计算机编程语言来说,数值型变量通常是连续的,文本型变量通常是不连续的。对于统计变量来说也存在连续不连续问题。如果随机变量中所有取值都可以逐个列举出来,则这个变量为离散型变量;而如果随机变量的所有取值无法逐个列举出来,而是取数轴上某一区间内的任一点。
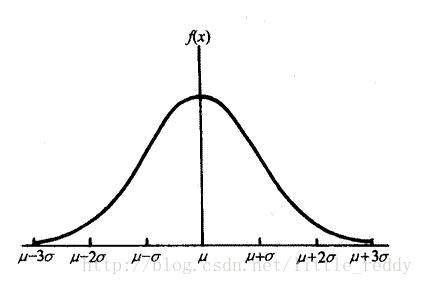
当f(x)来表示连续性随机变量时,我们将f(x)称为概率密度函数。对于连续性随机变量中,最重要的一种随机变量是具有钟型概率分布的随机变量,如下图所示。人们称它为正太随机变量,相应的概率分布成为正态分布。我们在以后博客中要讨论的很多统计和地统计方法都是加上变量服从正态分布的。
五. 参数估计与假设检验
当我们采集了一个样本,并且计算出这个样本的一些统计量,如均值、方差。我们可不可以说总体和这个样本有着一样的均值、方差?如果我们样本量非常接近总体数量,比如10000人中,我们统计了9990人,这时候我们可以比较有底气的说:嗯,总体均值差不多就是这个数了!但是通常来说,采集的样本量只占总体很小一部分,这时我们就很没有底气了。
为了解决这些问题,人们陆陆续续地发明了参数估计和假设检验,这两种方法都是假设数据基于某种分布,然后用样本的统计量来估计总体的统计量。前者就是单纯地回答了上面的问,他说:
被逼着做了这么多设定,总算可以推断出一个靠谱的结果了。这就是参数估计的思想,基于以下假设的前提下,根据数据的分布情况,用样本的统计量来估计总体的统计量。当然样本量小,或者服从别的分布也有对应的估计方式,在此不多说了。
而假设检验呢,则是另一种思路。
在空间插值中其实是有用到参数估计和假设检验的思想的,但那是在实现克里金插值时的中间过程,我们在选择插值方法时并不用考虑他们的原理也并不会接触他们的应用,所以我们只要知道他们大致是干什么的就足够了。
六. 回归与插值
对于数据的多个数值型变量,如果他们之间存在某种关系,我们就称之为相关,基于他们之间的相关性分析方法叫做回归;相关与回归是处理变量之间关系的一种统计方法。比如我们统计了一群人的收入水平和他们受教育程度两个变量,经过研究发现这两个变量之间存在某种关联,我们就说二者之间属于相关关系。这时我们就要提问了:两个变量之间真的有关系吗?有什么样的关系?关系强弱如何?样本所反映的变量之间关系能否代表总体变量之间的关系?
当这帮人也被折腾的够呛之后,他们在假设数据符合某些要求的情况下,用相关系数来来代表变量之间的相关关系,并基于相关系数建立了回归分析思想。

在地统计中,回归分析的一方面体现就叫做插值。(扯了这么多,插值总算是闪亮登场了。)大家想一想,假设把地理位置作为一个变量,那么我们就建立一个基于空间位置和属性值的回归分析。这样的关系建立之后,就可以根据观测点的属性值来预测出已知空间位置的属性值了!
(突然觉得前五点都不用说,只要说第六点就行。但是转念一想辛辛苦苦写了这么久不能就放到回收站,就辛苦大家看吧。)
文章来源:http://blog.csdn.net/little_reddy/article/details/53508682
在工作中经常碰到这样的问题:我这组数据应该用什么插值比较好?ArcGIS中的这些插值方法哪个最快?哪个效果最好?
碰到这种问题,ArcGIS地统计模块帮助文档中给出了插值方法分类树,对应插值方法分类自己进行决策就行了。
但实际情况并不如此简单,先不谈这个分类树中并没有介绍几种克里金插值的区别问题,其中很多分类也并不明确,比如不平滑、中等平滑和平滑这样含糊不清的分类就让人很难抉择;而且这个分类树最重要的问题是,很多专有名词并不容易被理解,比如:什么是假设条件的级别?什么是预测值的不确定性?什么是空间自相关?
我认为作为GIS从业人员或GIS学生,想要使用ArcGIS平台对空间数据进行插值,固然不需要非常专有的数学、统计知识,但是对统计、地统计的一些基本概念还是需要的。这个系列博客会把空间插值要用到的一下相关名称、原理做一些基本的介绍,并比较各个插值方法不同的适用性。
作为这个系列的第一篇博客,我在这里先介绍一些空间插值会应用到的基本的统计概念,然后将他们类比到地统计任务中。
一. 总体、样本、测量值和统计量
总体是考察对象的全体,样本是我们为了得知总体的一些信息而采集的对象集合,测量值顾名思义就是样本的值,而统计量是总体或样本值进行一些统计分析后得出的结果,如均值,极值等。
比如某个产品,工厂生产了10000件,质检部门对这些产品随机抽取了50件进行质检,查出来50件的重量平均值是100公斤;这10000件就是总体,50件就是样本,而重量平均值就是一个统计量。但是要注意的是,即便样本数量再接近总体数量,样本的统计量也绝不等于总体的统计量,哪怕这10000件产品中抽查了9999件,重量平均值是100公斤,也不能说加上最后一件后均值仍然是100公斤。
放到插值分析中来说,这片区域所有位置是总体,观测点为样本。但是要注意的是,不仅仅是观测点的值可以作为测量值计算相关统计量,观测点的位置、观测时间在地统计中也是重要的信息。
二. 两个重要的统计量
在统计分析中,数值型数据两个最重要的统计量分别是均值和方差。
均值是数据集中趋势的最重要测量值。从统计思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
方差是个变量值与平均数之差的平方的平均数。他在数学处理上是通过平方的办法消去差的正负号,然后进行平均。方差的平方根称为标准差。方差(或标准差)可以较好地反映出数据的离散程度,是实际中应用最广的离散程度测量值。
三. 描述性统计和推断性统计
统计操作可以分为两类,描述性统计和推断性统计。他们并不是并列存在的,推断性统计实际上实在描述性统计的基础上进行更深层次的分析。
- 描述性统计:指对样本的测量值进行相关统计量计算、分析,并进行相应的可视化。还包括趋势分析和相关性分析等。 ArcGIS地统计模块中提供了一系列探索性空间数据分析 (ESDA) 图表,他们提供了:空间数据的分布检查、全局异常值和局部异常值的查找、全局趋势的分析、局部变化的检查以及空间自相关的检查。
- 推断性统计:指利用样本统计量对总体统计量的估计过程,包括参数估计和假设检验,回归分析。空间插值也属于推断性统计这一过程。
四. 变量的连续性与随机变量的分布
对于计算机编程语言来说,数值型变量通常是连续的,文本型变量通常是不连续的。对于统计变量来说也存在连续不连续问题。如果随机变量中所有取值都可以逐个列举出来,则这个变量为离散型变量;而如果随机变量的所有取值无法逐个列举出来,而是取数轴上某一区间内的任一点。
比如之前的例子,样本的测量值:重量,这就是一个连续型变量。
当f(x)来表示连续性随机变量时,我们将f(x)称为概率密度函数。对于连续性随机变量中,最重要的一种随机变量是具有钟型概率分布的随机变量,如下图所示。人们称它为正太随机变量,相应的概率分布成为正态分布。我们在以后博客中要讨论的很多统计和地统计方法都是加上变量服从正态分布的。
五. 参数估计与假设检验
当我们采集了一个样本,并且计算出这个样本的一些统计量,如均值、方差。我们可不可以说总体和这个样本有着一样的均值、方差?如果我们样本量非常接近总体数量,比如10000人中,我们统计了9990人,这时候我们可以比较有底气的说:嗯,总体均值差不多就是这个数了!但是通常来说,采集的样本量只占总体很小一部分,这时我们就很没有底气了。
这时候有个统计学家冒出来说,我这个样本量虽然不多,但是我的样本方差很小啊,说明我这个数据的离散程度很低,那么即便样本量不多我也稍微有点信心说总体的均值差不多就是我样本的均值了!
这时候别人就会问了,你方差小,是多小?你这种情况适用于总体和样本分布为多少的数据?总体均值和样本均值差不多,是差了多少?
为了解决这些问题,人们陆陆续续地发明了参数估计和假设检验,这两种方法都是假设数据基于某种分布,然后用样本的统计量来估计总体的统计量。前者就是单纯地回答了上面的问,他说:
如果我的样本量大于30,数据服从正态分布,基于这个总体的历史情况,它的方差我是已知的,那么我可以设置一个置信水平,比如95%,那么总体的均值有95%的可能就落在这个区间内!
被逼着做了这么多设定,总算可以推断出一个靠谱的结果了。这就是参数估计的思想,基于以下假设的前提下,根据数据的分布情况,用样本的统计量来估计总体的统计量。当然样本量小,或者服从别的分布也有对应的估计方式,在此不多说了。
而假设检验呢,则是另一种思路。
还是这个问题,你问的这些问题我答不上来,但是我还是觉得这个样本的均值差不多就是总体的均值。那我就假设它靠谱,然后根据变量的分布情况和均值方差以及置信水平来做一个验证,如果验证发现不合适那我认怂,这个样本均值确实不能代表总体均值;但是验证结果没有对我不利信息,那不好意思,谁有不能拒绝我这个假设。
在空间插值中其实是有用到参数估计和假设检验的思想的,但那是在实现克里金插值时的中间过程,我们在选择插值方法时并不用考虑他们的原理也并不会接触他们的应用,所以我们只要知道他们大致是干什么的就足够了。
六. 回归与插值
另外一波人看这帮统计学家这么折腾,看得是一头汗:这也太绕了,看来用样本单一属性值来估计总体值确实不太容易,要不我们换个思路,我们统计出两个变量,然后找到他们的关系,就可以用一个变量预测另一个了。
对于数据的多个数值型变量,如果他们之间存在某种关系,我们就称之为相关,基于他们之间的相关性分析方法叫做回归;相关与回归是处理变量之间关系的一种统计方法。比如我们统计了一群人的收入水平和他们受教育程度两个变量,经过研究发现这两个变量之间存在某种关联,我们就说二者之间属于相关关系。这时我们就要提问了:两个变量之间真的有关系吗?有什么样的关系?关系强弱如何?样本所反映的变量之间关系能否代表总体变量之间的关系?
当这帮人也被折腾的够呛之后,他们在假设数据符合某些要求的情况下,用相关系数来来代表变量之间的相关关系,并基于相关系数建立了回归分析思想。
在地统计中,回归分析的一方面体现就叫做插值。(扯了这么多,插值总算是闪亮登场了。)大家想一想,假设把地理位置作为一个变量,那么我们就建立一个基于空间位置和属性值的回归分析。这样的关系建立之后,就可以根据观测点的属性值来预测出已知空间位置的属性值了!
(突然觉得前五点都不用说,只要说第六点就行。但是转念一想辛辛苦苦写了这么久不能就放到回收站,就辛苦大家看吧。)
文章来源:http://blog.csdn.net/little_reddy/article/details/53508682
