
聚类和异常值分析(Anselin Local Moran's I)修正篇
分享
-
2016-01-26
写这篇文章之前,首先对所有的读者进行诚挚的歉意,在白话空间统计十七章聚类和异常值分析里面,对HH\HL\LH\LL四种情况的描述出现了严重的问题,根据ArcGIS计算出来的数据就直接进行描述,结果发生了想当然的结果。
在这里诚恳而且郑重的道歉,特别是对那些被我的文章误导了的同学。
第二,对河北师大李同学的提醒进行真诚的感谢,如果不是你的提醒,我可能还不知道我发生了如此重大的错误。正因为李同学的提醒,虾神重读了luc Anselin教授1995年的论文《Local Indicators of Spatial Association-LISA》,并且专门使用了GeoDa进行验证,最后终于发现了上一篇文章里面对于四种结论的图片是错误的,错得相当严重,所以本文对十七章进行全面修正。
在anselin教授的论文里面,对HH\HL\LH\LL四种情况的象限分配描述是这样的:

具体来解释就是:

而我在上一篇文章里面,把第三第四象限搞反掉了,这点是错误的,如下:

这样就是正确的,但是为什么会出现如此严重的错误呢?是因为在ArcGIS里面,只会去计算Moran's i和z得分,所以部分只使用ArcGIS而没有用过GeoDa的人(主要是虾神这种老是自以为是而且还有些孤陋寡闻的土鳖虾),把X轴和Y轴当成了莫兰指数和Z得分,想理所当然的画出了一个散点图,而且还洋洋得意的以为是对的。
实际上第十七话的图和解释是严重错误!请大家原谅。
实际上第十七话的图和解释是严重错误!请大家原谅。
实际上第十七话的图和解释是严重错误!请大家原谅。
重要的事情说三遍,诚恳道歉。
在重读了LISA这篇论文之后,发现X轴Y轴的意思完全和直接计算出来的moran's i和z得分完全不是一回事,实际上,是这样的:
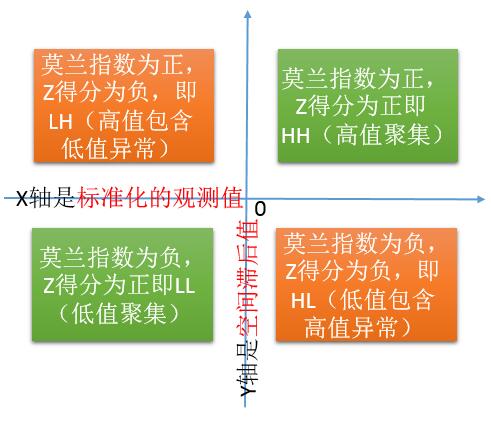
而我上次写成了这个样子:

两个轴的解释如下:
首先,X是标准化之后的观测值: 比如我用中国2012年的市级人口数据(男),那么计算如下:

然后Y轴是所谓的空间滞后值(spatial lag),对这个空间滞后模型也是Anselin教授在1988年提出来的,其表示的是:
该观测值周围邻居的加权平均。计算过程如下: 首先从空间权重矩阵中,获取该要素的邻接要素,比如2388(石家庄)这个要素,他的邻接要素一共有6个,如下:

然后获取6个邻接要素的标准化观察值,并且进行加权平均,最后将这个加权平均值赋予中心要素。
全部计算完成之后,X轴和Y轴就全部计算出来了。
接下去就可以画出散点图了:

剩下的内容,就是通过Z得分和P值,来确定该数据是否具有统计显著性:
首先还是P值,P值没有意义的话,就是瞎猜,所以首先按照最高等级的99%可信度,将P值设为0.01,绘制如下:

大部分数据集中在第三象限,也就是LL(低值聚类),当我们把置信度调整到0.05,再看:

把四个象限尺度放大:

最后,贴出Luc Anselin教授的原始论文地址:
http://isites.harvard.edu/fs/d ... A.pdf
geoda软件的下载地址大家请自行搜索(最后一个好消息:这个东东下载不用翻墙哦……此次应有掌声)
最后,再次对河北师大李同学表示感谢。
文章来源:http://blog.csdn.net/allenlu2008/article/details/50674929
在这里诚恳而且郑重的道歉,特别是对那些被我的文章误导了的同学。
第二,对河北师大李同学的提醒进行真诚的感谢,如果不是你的提醒,我可能还不知道我发生了如此重大的错误。正因为李同学的提醒,虾神重读了luc Anselin教授1995年的论文《Local Indicators of Spatial Association-LISA》,并且专门使用了GeoDa进行验证,最后终于发现了上一篇文章里面对于四种结论的图片是错误的,错得相当严重,所以本文对十七章进行全面修正。
在anselin教授的论文里面,对HH\HL\LH\LL四种情况的象限分配描述是这样的:
具体来解释就是:
而我在上一篇文章里面,把第三第四象限搞反掉了,这点是错误的,如下:
这样就是正确的,但是为什么会出现如此严重的错误呢?是因为在ArcGIS里面,只会去计算Moran's i和z得分,所以部分只使用ArcGIS而没有用过GeoDa的人(主要是虾神这种老是自以为是而且还有些孤陋寡闻的土鳖虾),把X轴和Y轴当成了莫兰指数和Z得分,想理所当然的画出了一个散点图,而且还洋洋得意的以为是对的。
实际上第十七话的图和解释是严重错误!请大家原谅。
实际上第十七话的图和解释是严重错误!请大家原谅。
实际上第十七话的图和解释是严重错误!请大家原谅。
重要的事情说三遍,诚恳道歉。
在重读了LISA这篇论文之后,发现X轴Y轴的意思完全和直接计算出来的moran's i和z得分完全不是一回事,实际上,是这样的:
而我上次写成了这个样子:
两个轴的解释如下:
首先,X是标准化之后的观测值: 比如我用中国2012年的市级人口数据(男),那么计算如下:
然后Y轴是所谓的空间滞后值(spatial lag),对这个空间滞后模型也是Anselin教授在1988年提出来的,其表示的是:
该观测值周围邻居的加权平均。计算过程如下: 首先从空间权重矩阵中,获取该要素的邻接要素,比如2388(石家庄)这个要素,他的邻接要素一共有6个,如下:
然后获取6个邻接要素的标准化观察值,并且进行加权平均,最后将这个加权平均值赋予中心要素。
全部计算完成之后,X轴和Y轴就全部计算出来了。
接下去就可以画出散点图了:
剩下的内容,就是通过Z得分和P值,来确定该数据是否具有统计显著性:
首先还是P值,P值没有意义的话,就是瞎猜,所以首先按照最高等级的99%可信度,将P值设为0.01,绘制如下:
大部分数据集中在第三象限,也就是LL(低值聚类),当我们把置信度调整到0.05,再看:
把四个象限尺度放大:
最后,贴出Luc Anselin教授的原始论文地址:
http://isites.harvard.edu/fs/d ... A.pdf
geoda软件的下载地址大家请自行搜索(最后一个好消息:这个东东下载不用翻墙哦……此次应有掌声)
最后,再次对河北师大李同学表示感谢。
文章来源:http://blog.csdn.net/allenlu2008/article/details/50674929
